In “Working Effectively with Legacy Code” (ISBN-9787111466253) Michael C. Feathers defines it as “code without a unit test.” I agree that code without “unit test” is legacy code, but I don’t consider that only having unit tests translates to your code being a modern “Lisa” program. I prefer to consider legacy code anything in which making any change is hard, costly, and risky because the maintainability is not high enough for different reasons that include:
- Not having a comprehensive test suite
- Poor documentation
- Low code quality
I am pretty sure that while you are reading this, more than one of you is writing legacy code because legacy does not mean “old.”
Maintainability
According to IEEE, maintainability is:
“The ease with which a software system or component can be modified to correct faults, improve performance or other attributes, or adapt to a changing environment.”
So let’s discuss some topics that can make our code more maintainable.
Automated Testing
This is a must. We cannot change anything with any degree of trust without having a good automated test suite to support us.
Salesforce has a really good API to help developers with “unit testing” (the tests we mostly write in Salesforce are integration as we are interacting with a database instead of mocking it). Also, Salesforce requires us to have 75% of code coverage over all of the org to be able to promote to production, which is great…but is it enough?
For example, imagine you have this code:
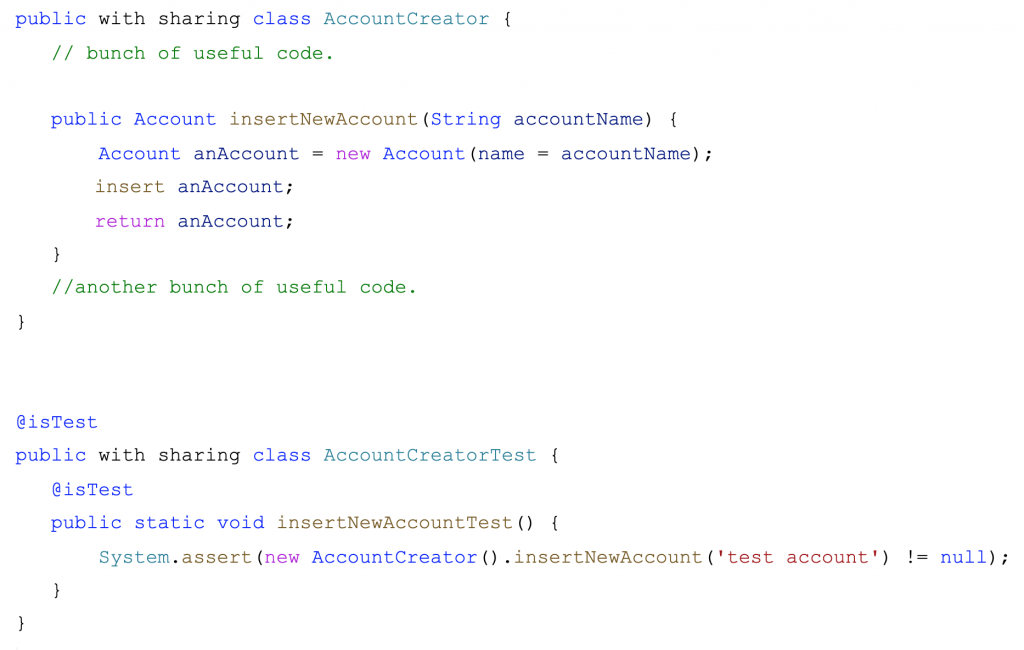
This test passes, 100% code coverage. But another developer calls a new AccountCreator().insertNewAccount('') and the user sees an exception. Chances are the developer who created this class was doing test-driven development (TDD) but didn’t take time to think about the business restrictions (account name cannot be null or empty). There is no test checking that the code is doing this validation.
So having high code coverage is not enough, we have to make sure that we have covered all possible scenarios (happy paths, failures paths, border cases…all of them).
Documentation
We write code that lives for years and once in a while a person has to make a change. This person won’t be the same person as the one who coded it – even if they share the same ID number, phone number, or Instagram username, the programmer from the future probably has forgotten some aspect of the code. So we need some degree of documentation in our classes.
I wanna discuss the two main types of in-code documentation. First, let me show one example:
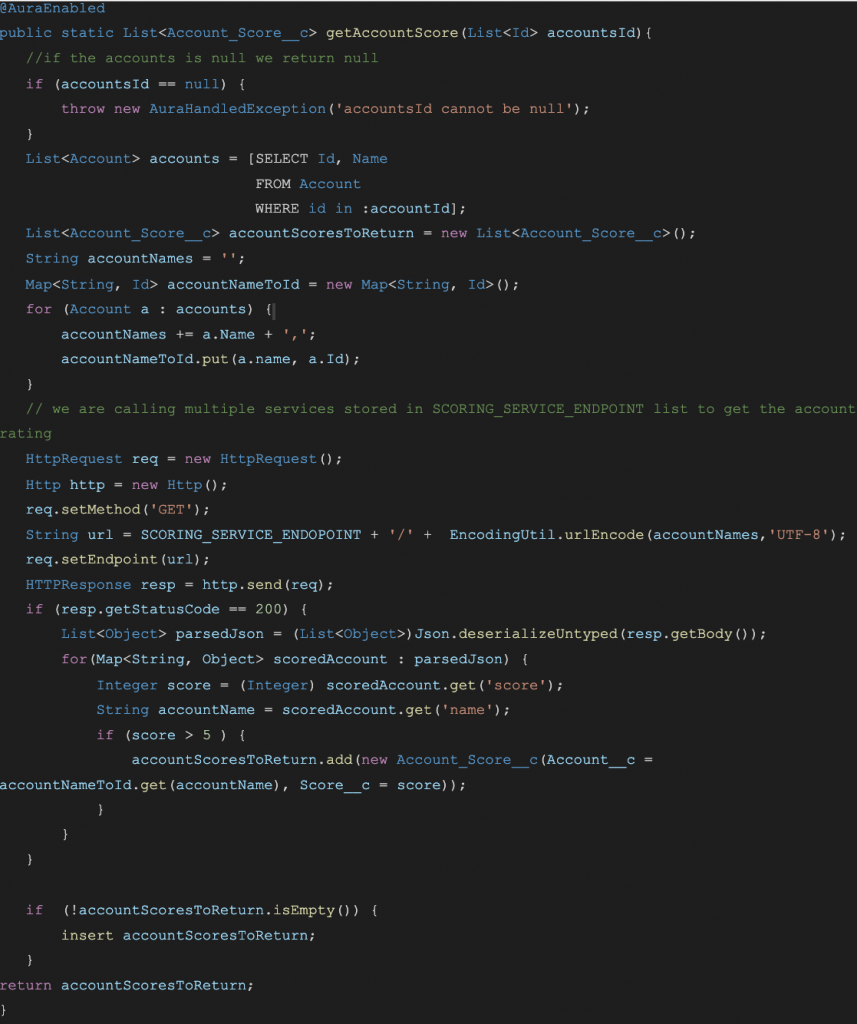
Let’s try to fix this with some tools:
*doc documentation (ApexDoc in the case of Apex)
A bunch of tools exists that allows us to put some special comments before classes and method declarations which can be parsed to generate documentation automatically. And the good part, you have the documentation in the same place as the code. In ApexDoc, the comment has to start with the /** instead of the regular /* Apex comment block and we have some tags to indicate what we are writing. Here’s an example:

- @description: A high-level human-readable and understandable description of what the method is doing. I prefer to put an easily understandable and quick to read first line about what the method is doing. A really important detail that the developer needs to know about the method like if a web service is being used, I put that in the next line (but not going very deeply into implementation details).
- @param: For each parameter, the method takes, we have to indicate the type, preconditions, and a description of what it is intended for.
- @returns: The returning type and description (if the method is not void).
- @throws: The exception it could throw and when it would do it.
The last topic about this is where the ApexDoc should be present. There are two approaches to this:
- Public classes and methods
- Every class and method
The main advantage of putting documentation in public classes and methods is that after we shared our code with the world, changing the contract we defined is not so simple (without breaking other people’s code) so we can be quite sure that the ApexDoc does not become obsolete (yes, we need to maintain the ApexDoc, too).
I prefer to put it everywhere and be sure the comments get updated when there are changes in the methods because private methods are code, too. They deserve respect and we will need to read them anywhere. We need to be kind to the next developer changing this code (especially because the next one could be ourselves of the future and I don’t want to aggravate them).
So now we have all our methods documented and we can skip reading that long and hard method that the piece of code I am working on calls (we go into details if and only if we need it).
Comments on implementation code
When I started to study computer science, a professor told me that comments are very important.
Well, I completely disagree with that idea in real life.
Code has to be self-descriptive and if we need to put a comment in it, we must be sure there is nothing else we can do to make the code more understandable without the comment. A comment line in the code is a new code line that needs to be maintained and it took development time to put it there. It also cannot be tested, so the chances are the comment ends up saying something that the code is not doing. Read the code carefully and tell me if you could find any discrepancies.
We will tackle how to reduce comment quantity shortly, but first check really good code comments here on Stack Overflow: Best Comments in Source Code You Have Ever Encountered
I really loved this one:
//When I wrote this, only God and I understood what I was doing
//Now, God only knows
Code Quality
This is the last topic I wanna cover today and I will only scratch the surface. In particular, I want to discuss how we can write our code to communicate with other developers in a way that is easier, faster, and clearer. Code should be self-explanatory and we should hide the implementation details until it is not possible to anymore. Ideally, our public method should be written as a declaration of the developer’s intentions and we leave the implementation details (the imperative part) to private methods (but we should not chain many private methods calls as it forces the developer to go forward and backward and is not optimal).
Let’s start with the method I showed you in the last section:
In this method, we find three different parts:
- Collect data from parameters
- Do business logic
- Save and return the result (technically a method should do only one thing and do it well…this does two, but it is part of the trade-off we have to make in real life)
So let’s start with the first part:
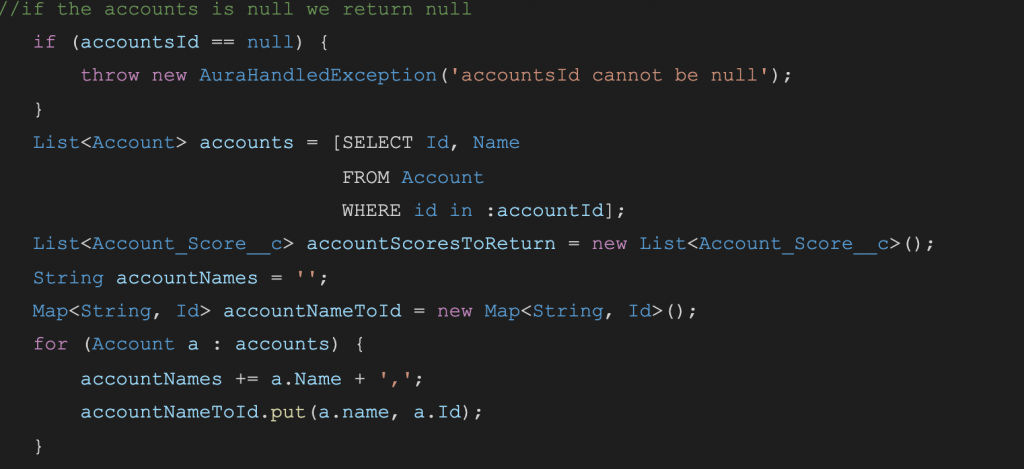
- We see the comment is wrong and useless so we delete it.
- SOQL query is already declarative (the query has Salesforce best practices issues, but I do not want to focus on this right now), so we can’t hide any implementation details.
- We have some variable declarations:
- accountScoresToReturn: This variable is self-explanatory: we are going to return this list.
- accountNames: Ok, they are account names but which account names??
- accountNameToId: Another good name, we know what we are going to store in it.
- We have an iteration: This is a candidate to split into another method. Unfortunately, we can’t do it without impacting the overall performance or quality (we can’t return two values in Apex, so we need two methods with two iterations or a function that returns a string and has side-effects of populating the map). But reading this block we start to figure out what accountNames is for. We concatenate the accountNames with “,” between them, but we find out that the variable accountName is not expressive enough so we are going to look in the code to figure out what it is.
Second block:
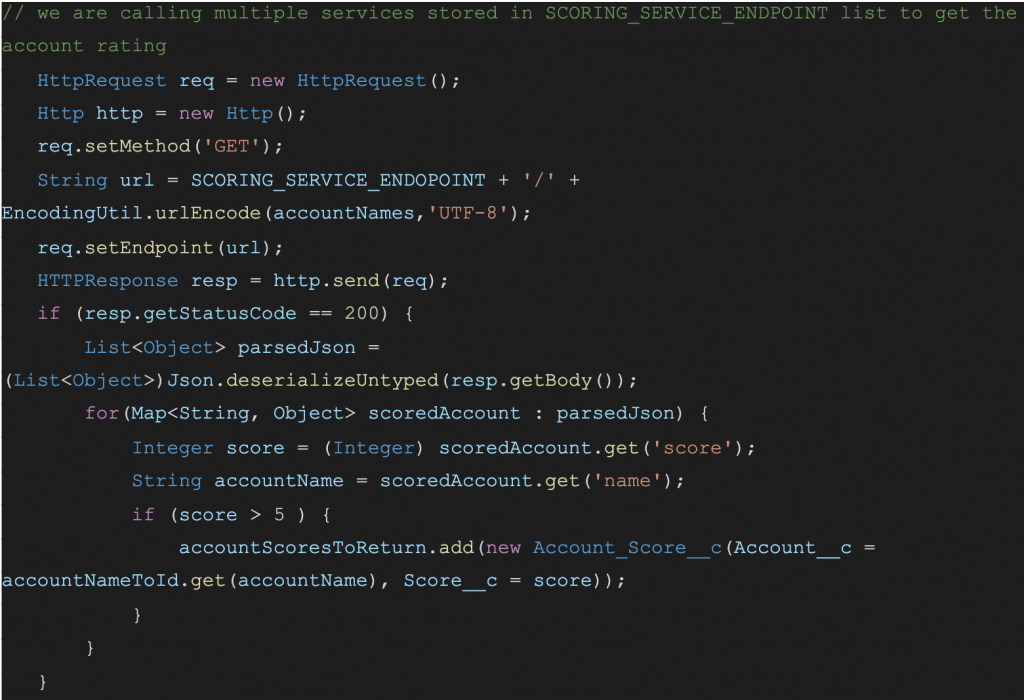
This block mainly does two things:
- It calls a webservice and parses the result
- It gets the higher score accounts
And there are plenty of implementation details.
First, we tackle the invocation of the service. It requires the account name string and returns the parsed JSON object. So, let’s split this other method:
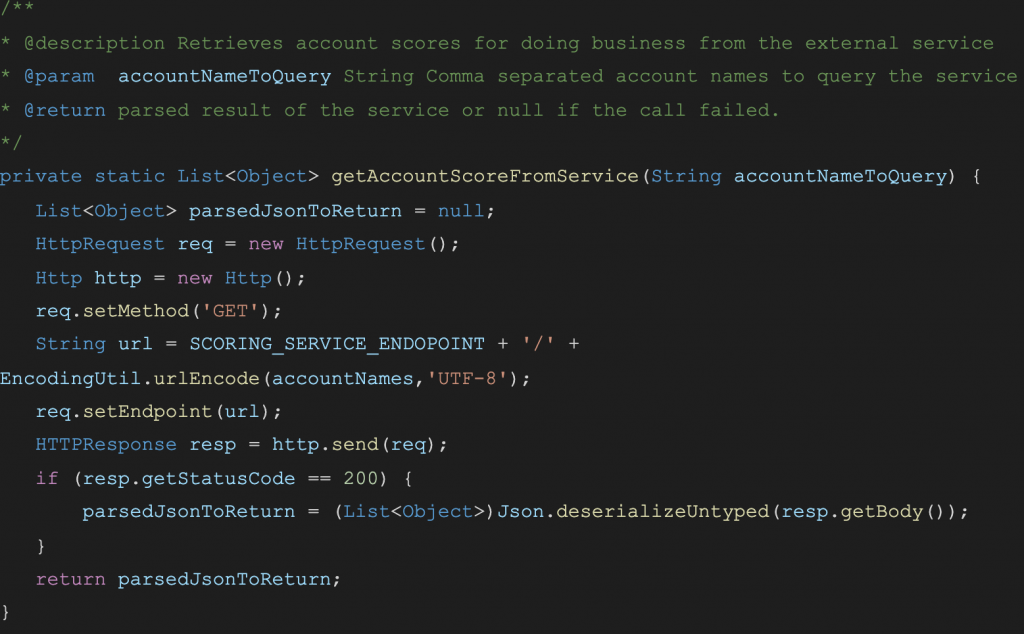
And our main method changes to:
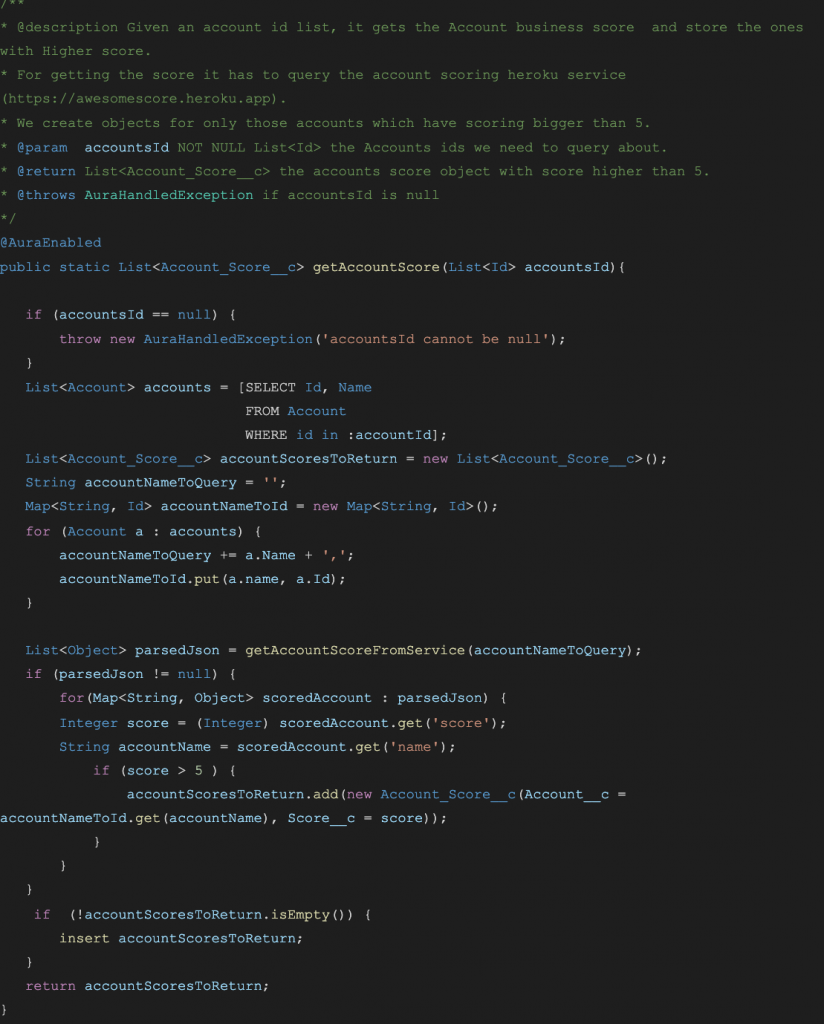
Let’s tackle the second part of the business logic. Before we do this, do not forget to run the complete test suite we have. The business logic iterates over the parsedJson object and selects those that score higher than 5. So we are going to split it into another method which takes parsedJson and returns the List of selected accounts:
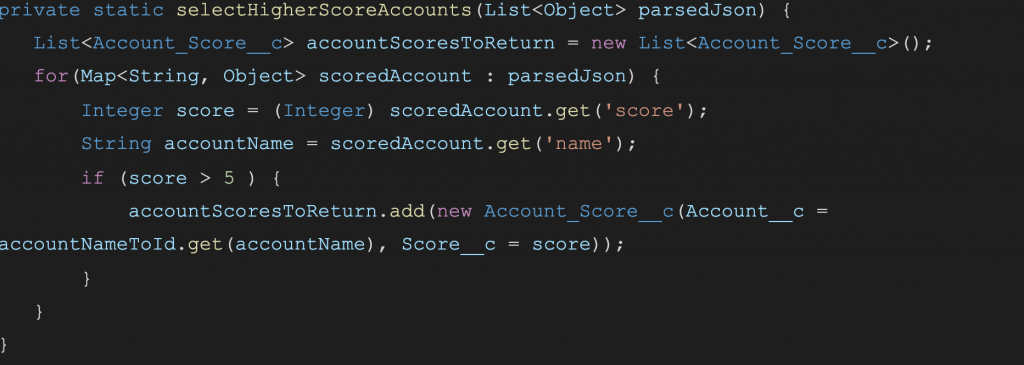
And our main method changes to:
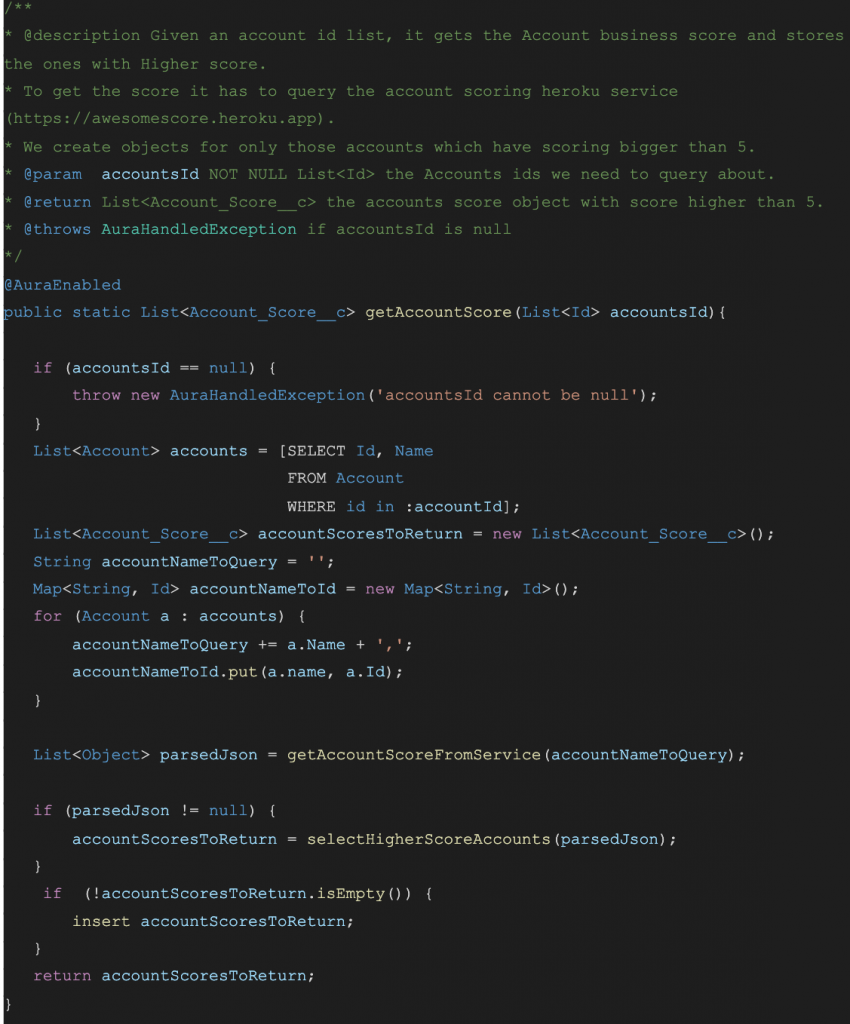
Finally, we have the part of the code that returns data. Most of the time this part just returns a value or insert for the database.
Conclusion
One of the most important attributes of the work we do is the maintainability of the code we write. We must ensure we are using all the tools we have to enable this. There are hundreds more topics and tools to cover regarding how to create maintainable code, but everything starts with the three points I covered here:
- Automated testing
- Documentation
- Code quality
Don’t forget you are going to spend more time reading the code than actually writing it. So you should take the time necessary to make it easier to read.
Coming back to our friends, we have Maggie: